Difan Liu
I am a research scientist at Adobe Research , where I work on computer graphics, computer vision and machine learning.
I received my PhD from UMass Amherst advised by Evangelos Kalogerakis . Prior to UMass Amherst, I got my bachelor's degree with honors in Electrical Engineering from University of Science and Technology of China .
Internships:
Email /
Research
Research
My research interests include generative models, multimodal generation and editing. I am
particularly interested in the synthesis and editing of images, video and vector graphics based on machine learning.
VEGGIE: Instructional Editing and Reasoning of Video Concepts with Grounded Generation
Shoubin Yu *,
Difan Liu *,
Ziqiao Ma *,
Yicong Hong ,
Yang Zhou ,
Hao Tan ,
Joyce Chai ,
Mohit Bansal
ICCV , 2025 Project
DOLLAR: Few-Step Video Generation via Distillation and Latent Reward Optimization
Zihan Ding ,
Chi Jin ,
Difan Liu ,
Haitian Zheng ,
Krishna Kumar Singh ,
Qiang Zhang ,
Yan Kang ,
Zhe Lin ,
Yuchen Liu
ICCV , 2025 Project
Rethinking Layered Graphic Design Generation with a Top-Down Approach
Jingye Chen ,
Zhaowen Wang ,
Nanxuan Zhao ,
Li Zhang ,
Difan Liu ,
Jimei Yang ,
Qifeng Chen
ICCV , 2025 pdf
VideoGigaGAN: Towards Detail-rich Video Super-Resolution
Yiran Xu ,
Taesung Park ,
Richard Zhang ,
Yang Zhou ,
Eli Shechtman ,
Feng Liu ,
Jia-Bin Huang ,
Difan Liu
CVPR , 2025 Project
Progressive Autoregressive Video Diffusion Models
Desai Xie ,
Zhan Xu ,
Yicong Hong ,
Hao Tan ,
Difan Liu ,
Feng Liu ,
Arie Kaufman ,
Yang Zhou
CVPR CVEU Workshop , 2025 pdf
Visual Persona: Foundation Model for Full-Body Human Customization
Jisu Nam ,
Soowon Son ,
Zhan Xu ,
Jing Shi ,
Difan Liu ,
Feng Liu ,
Aashish Misraa ,
Seungryong Kim ,
Yang Zhou
CVPR , 2025 Project
Move-in-2D: 2D-Conditioned Human Motion Generation
Hsin-Ping Huang ,
Yang Zhou ,
Jui-Hsien Wang ,
Difan Liu ,
Feng Liu ,
Ming-Hsuan Yang ,
Zhan Xu
CVPR , 2025 Project
Customize-A-Video: One-Shot Motion Customization of Text-to-Video Diffusion Models
Yixuan Ren ,
Yang Zhou ,
Jimei Yang ,
Jing Shi ,
Difan Liu ,
Feng Liu ,
Mingi Kwon ,
Abhinav Shrivastava
ECCV , 2024 Project
HARIVO: Harnessing Text-to-Image Models for Video Generation
Mingi Kwon ,
Seoung Wug Oh ,
Yang Zhou ,
Difan Liu ,
Joon-Young Lee ,
Haoran Cai,
Baqiao Liu,
Feng Liu ,
Youngjung Uh
ECCV , 2024 Project
VecFusion: Vector Font Generation with Diffusion
Vikas Thamizharasan *,
Difan Liu *,
Shantanu Agarwal,
Matthew Fisher ,
Michaël Gharbi ,
Oliver Wang ,
Alec Jacobson ,
Evangelos Kalogerakis
CVPR , 2024 (Highlight) PDF
NIVeL: Neural Implicit Vector Layers for Text-to-Vector Generation
Vikas Thamizharasan ,
Difan Liu ,
Matthew Fisher ,
Nanxuan Zhao ,
Evangelos Kalogerakis ,
Michal Lukáč
CVPR , 2024 PDF
Visual Layout Composer: Image-Vector Dual Diffusion Model for Design Layout Generation
Mohammad Amin Shabani ,
Zhaowen Wang ,
Difan Liu ,
Nanxuan Zhao ,
Jimei Yang ,
Yasutaka Furukawa
CVPR , 2024 Project
Attention-Driven Training-Free Efficiency Enhancement of Diffusion Models
Hongjie Wang ,
Difan Liu ,
Yan Kang ,
Yijun Li ,
Zhe Lin ,
Niraj Jha ,
Yuchen Liu
CVPR , 2024 PDF
SNED: Superposition Network Architecture Search for Efficient Video Diffusion Model
Yan Kang ,
Yuchen Liu ,
Difan Liu ,
Tobias Hinz ,
Feng Liu ,
Yanzhi Wang
CVPR , 2024 PDF
LRM: Large Reconstruction Model for Single Image to 3D
Yicong Hong ,
Kai Zhang ,
Jiuxiang Gu ,
Sai Bi ,
Yang Zhou ,
Difan Liu ,
Feng Liu ,
Kalyan Sunkavalli ,
Trung Bui ,
Hao Tan
ICLR , 2024 (Oral Presentation) PDF
/
Project
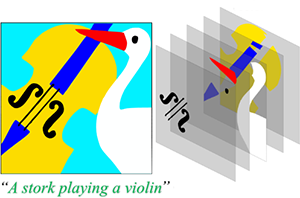
ASSET: Autoregressive Semantic Scene Editing with Transformers at High Resolutions
Difan Liu ,
Sandesh Shetty,
Tobias Hinz ,
Matthew Fisher ,
Richard Zhang ,
Taesung Park ,
Evangelos Kalogerakis
SIGGRAPH - Journal Track , 2022 PDF(low-res)
/
PDF(high-res)
/
Project
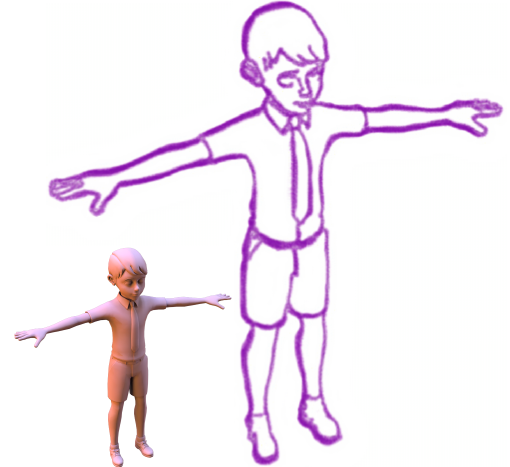
Neural Strokes: Stylized Line Drawing of 3D Shapes
Difan Liu ,
Matthew Fisher ,
Aaron Hertzmann ,
Evangelos Kalogerakis
ICCV , 2021 PDF
/
Project
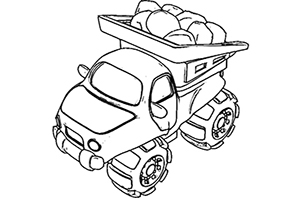
Neural Contours: Learning to Draw Lines from 3D Shapes
Difan Liu ,
Mohamed Nabail,
Aaron Hertzmann ,
Evangelos Kalogerakis
CVPR , 2020 PDF
/
Project
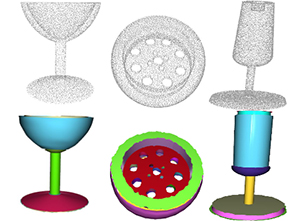
ParSeNet: A Parametric Surface Fitting Network for 3D Point Clouds
Gopal Sharma ,
Difan Liu ,
Subhransu Maji ,
Evangelos Kalogerakis ,
Siddhartha Chaudhuri ,
Radomír Měch
ECCV , 2020 PDF
/
Project
Neural Shape Parsers for Constructive Solid Geometry
Gopal Sharma ,
Rishabh Goyal,
Difan Liu ,
Evangelos Kalogerakis ,
Subhransu Maji
TPAMI , 2020 PDF
/
Code
Deep Part Induction from Articulated Object Pairs
Li Yi ,
Haibin Huang ,
Difan Liu ,
Evangelos Kalogerakis ,
Hao Su ,
Leonidas Guibas
SIGGRAPH Asia , 2018 PDF
/
Code
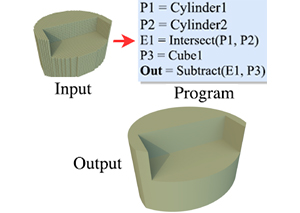
CSGNet: Neural Shape Parser for Constructive Solid Geometry
Gopal Sharma ,
Rishabh Goyal,
Difan Liu ,
Evangelos Kalogerakis ,
Subhransu Maji
CVPR , 2018 PDF
/
Code